
Question Answering System Note
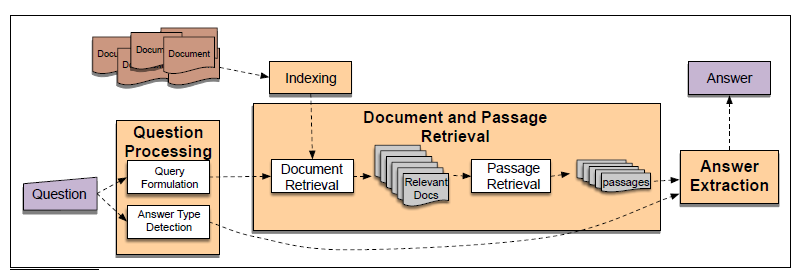
Takeaways on building an information retrieval QA System, notes from Speech and Language Processing 3rd ed P.403
Question Types
Factoid questions simple question, concise answer, usually one NER (most commertial systems)
- Who wrote the Declaration of Independence?
- What is the average age of the onset of autism?
- Where is Apple Computer based?
Complex (narrative) questions
- Describe the city you live in
Complex (opinion) questions
- Was the Gore/Bush election fair?
Factoid Questions
Information-retrieval or IR-based question answering relies on the vast quantities of textual information on the web or in collections like PubMed. Given a user question, information retrieval techniques first find relevant documents and passages. Then systems (feature-based, neural, or both) use reading comprehension algorithms to read these retrieved documents or passages and draw an answer directly from spans of text.
In the second paradigm, knowledge-based question answering, a system instead builds a semantic representation of the query, mapping What states border Texas? to the logical representation: lx:state(x)^borders(x; texas), or When was Ada Lovelace born? to the gapped relation: birth-year (Ada Lovelace, ?x). These meaning representations are then used to query databases of facts.
Answer Types
Question Classification
Finds the Answer Type
NER Categorizing the Answer Type
- Who founded Virgin Airlines? [PERSON]
- What Canadian city has the largest population? [CITY] [LOCATION]
If we know that the answer type for a question is a person, we can avoid examining every sentence in the document collection, instead focusing on sentences mentioning people.
Answer Type Taxonomy
Wordnet
Hand-built ontology
Supervised Learning
Trainined datasets with hand-labeled with answer type
Answer Type Word
Question Head Word The headword of the first NP after the question’s wh-word
- Which city in China has the largest number of foreign financial companies?
- What is the state flower of California?
In general, question classification accuracies are relatively high on easy question types like PERSON, LOCATION, and TIME questions; detecting REASON and DESCRIPTION questions can be much harder.
Passage Retrieval
Divide top n passages
Supervised Learning with some features, including:
- N of NER of the right type in the passage
- N of question keywords in the passage
- The longest exact sequence of question keywords that occurs in the passage
- The rank of the document from which the passage was extracted
- The proximity of the keywords from the original query to each other (Pasca 2003, Monz 2004).
- The number of n-grams that overlap between the passage and the question (Brill et al., 2002).
Answer type match:
True if the candidate answer contains a phrase with the cor- rect answer type.
• Pattern match: The identity of a pattern that matches the candidate answer. Number of matched question keywords: How many question keywords are contained in the candidate answer.
• Keyword distance: The distance between the candidate answer and query key- words (measured in average number of words or as the number of keywords that occur in the same syntactic phrase as the candidate answer).
• Novelty factor: True if at least one word in the candidate answer is novel, that is, not in the query.
• Apposition features: True if the candidate answer is an appositive to a phrase con- taining many question terms. Can be approximated by the number of question terms separated from the candidate answer through at most three words and one comma (Pasca, 2003).
• Punctuation location: True if the candidate answer is immediately followed by a comma, period, quotation marks, semicolon, or exclamation mark.
• Sequences of question terms: The length of the longest sequence of question terms that occurs in the candidate answer.
Key takeaways
In the answer generation task, it is about finding backup plans and ask questions as what if certain strategy fail. For example, in a simple factoid question such as “Who cook the dinner for Queen Cersei?” The answer will look for the NER tags [PERSON] first. But what if the answer text does not contain any NER tag? Then go find other related NER tags. What if there are more than one phrases with relevant NER tags? Go for the one that is closest in distance from the text’s root (dependency parsing). What if there are no phrases with NER tags at all? Find the pattern patch with the query. etc. At last, I found three strategies that are particularly useful in generating answers and coming up with the back-up plans: novelty factor, keyword distance, and pattern match.